# Flink之Checkpoints和Savepoints简介
# Checkpoints检查点机制
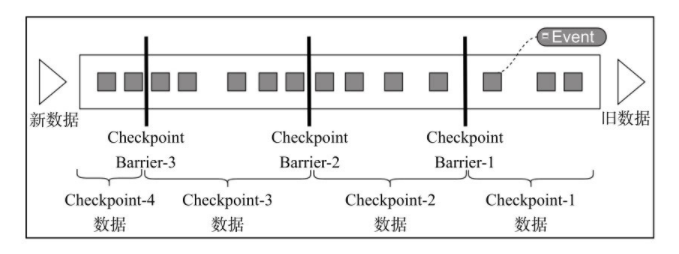
Flink中基于异步轻量级的分布式快照技术提供了Checkpoints容错机制,分布式快照可以将同一时间点Task/Operator的状态数据全局统一快照处理,包括前面提到的Keyed State和Operator State。如下图所示,Flink会在输入的数据集上间隔性地生成checkpoint barrier,通过栅栏(barrier)将间隔时间段内的数据划分到相应的checkpoint中。当应用出现异常时,Operator就能够从上一次快照中恢复所有算子之前的状态,从而保证数据的一致性。例如在KafkaConsumer算子中维护Offset状态,当系统出现问题无法从Kafka中消费数据时,可以将Offset记录在状态中,当任务重新恢复时就能够从指定的偏移量开始消费数据。对于状态占用空间比较小的应用,快照产生过程非常轻量,高频率创建且对Flink任务性能影响相对较小。checkpoint过程中状态数据一般被保存在一个可配置的环境中,通常是在JobManager节点或HDFS上。
默认情况下Flink不开启检查点的,用户需要在程序中通过调用enable-Checkpointing(n)方法配置和开启检查点,其中n为检查点执行的时间间隔,单位为毫秒。除了配置检查点时间间隔,请参考官方api文档。
# Savepoints
Savepoints是检查点的一种特殊实现,底层其实也是使用Checkpoints的机制。Savepoints是用户以手工命令的方式触发Checkpoint,并将结果持久化到指定的存储路径中,其主要目的是帮助用户在升级和维护集群过程中保存系统中的状态数据,避免因为停机运维或者升级应用等正常终止应用的操作而导致系统无法恢复到原有的计算状态的情况,从而无法实现端到端的Excatly-Once语义保证。